askSheng - let the AI flex for me
I just built askSheng, an AI assistant to help answer questions from recruiters and hiring managers about me.
The idea is simple: instead of me doing all the talking about what I’m good at, why not let an AI do the flexing for me? 😎
Links
- Application link: askSheng is intentionally designed to be accessed only by selected people via a magic link, so I won’t be sharing the link publicly here. But if you’re curious and want to give it a spin, feel free to email me at shengng325@gmail.com. I will be happy to share it!
- Github link: /askSheng
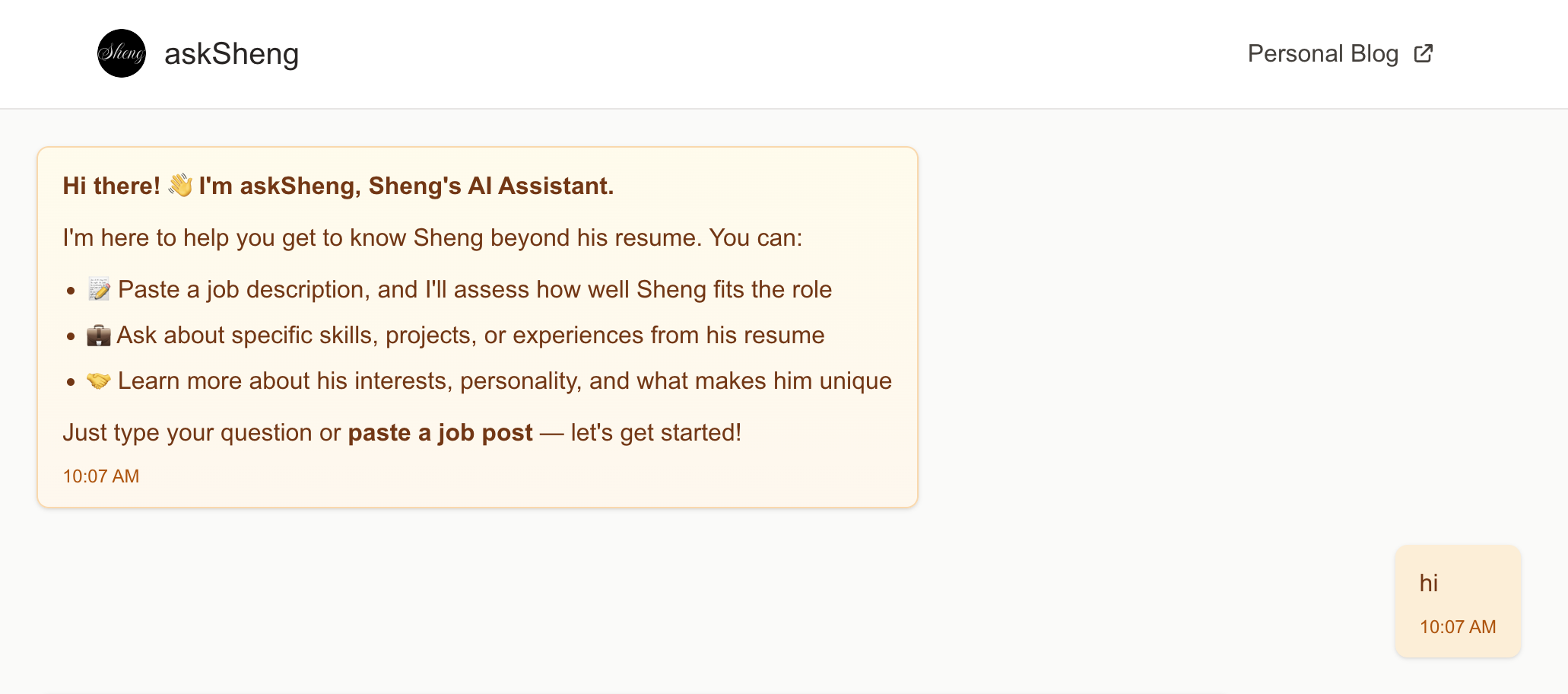
What is askSheng?
At a high level, askSheng is a chat interface powered by an OpenAI language model. It allows users to interact with an AI agent that knows about my professional experience, skills, and projects. When a job description is provided, the AI evaluates my fit for the role:
- If it’s a good fit, it explains why by highlighting relevant skills and past work.
- If it’s not, it provides reasons for the mismatch.
But behind the scenes, there’s more going on, including access control, prompt engineering, and session management.
Token-based access control
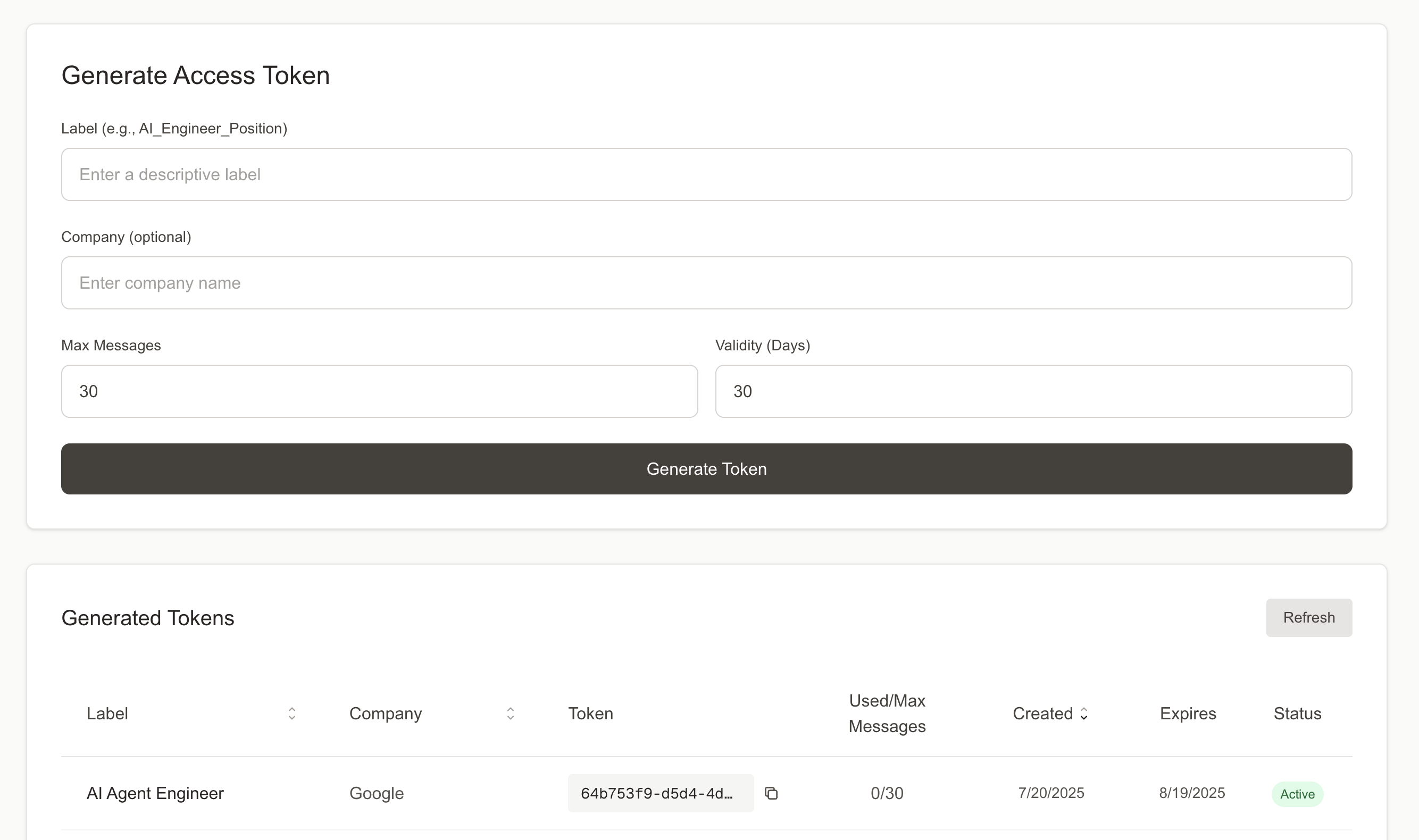 To control access, I implemented a token-based system.
To control access, I implemented a token-based system.
- I first generate a magic link via a private interface and assign it a label like the company name or job title.
- I then embed the magic link into my PDF resume submitted for a job application.
Why tokens?
Tokens serve two key purposes:
1. Access Control
Each token has a validity period and a maximum message count. This ensures the AI agent can only be accessed via a resume-linked magic link. While the link is shareable, the usage limits and revocation capability help prevent abuse. More importantly, it prevent spam that could burn through my OpenAI token quota.
2. Tracking and Analytics
With each token labeled, I can track when a recruiter clicks the link. This gives me valuable insight into whether my application was viewed and when it was viewed. It is useful for iterating on resume strategies or understanding hiring funnel behavior.
LLM evaluation and selection
I use OpenAI models primarily because I already had credits. My goal was to choose a lightweight, fast, and affordable model. Complex reasoning isn’t necessary for a resume Q&A use case.
Model Evaluation
I started with gpt-4o-mini. It’s fast, but I ran into limitations:
- Knowledge cutoff in 2023 means it hallucinated recent AI concepts.
- For example, it incorrectly expanded MCP as “Multi-agent Context Protocol” or misunderstood RAG as “Reinforcement Agent Generation”.
I then moved to gpt-4.1-mini, which has a later 2024 cutoff and significantly fewer hallucinations.
I intentionally avoided more expensive premium models to keep costs down — and gpt-4.1-mini strikes a solid balance between speed, accuracy, and price.
How does the AI agent know about me?
In large-scale agentic systems, we might use Retrieval-Augmented Generation (RAG) to feed dynamic context to the LLM. But that would be overengineered here.
For askSheng, I maintain a static knowledge-base.md file containing information about me, such as career history, skills, accomplishments, projects, etc. and pass into the LLM’s context window. It is a very simple yet effective way for this use case.
Session and Memory
Although token-based access control gives us a notion of “user sessions,” I intentionally choose not to persist chat history across sessions or page refreshes.
Why?
1. Token ≠ User Identity
A token link can be shared. So persisting chat history may result in a different person seeing a previous user’s conversation, which is not ideal.
2. Cost Consideration
Persisting memory increases context window size and inference cost. For a lightweight system, it’s not worth it.
3. Simple is better
While I considered using local storage to retain session data per browser, I opted for simplicity. On every new page load or refresh, a new session is started. We rely only on the messages from the current session as the LLM’s memory, meaning what the model “remembers” is just the ongoing chat, nothing is stored beyond the session
Analytics
When we have more data, we can have a lot of creative analytics ideas. I don’t plan to go deep here now, but these are the possible analytics ideas that we can do:
-
Click-through tracking: If a resume is submitted but the link is never clicked, it might indicate that the resume was filtered out early — possibly by an ATS.
-
A/B Testing (kind of): By sending different versions of my resume, I can loosely track which versions generate more engagement with this AI assistant.
Final thoughts
Will this tool actually be useful? I guess I’ll find out soon enough, once a few recruiters start chatting with my AI assistant.
As for the idea itself: I came up with it entirely on my own. Of course, in today’s world, it’s nearly impossible to claim something is 100% original. Someone out there might’ve built something similar. But askSheng wasn’t copied by anything I saw. It came from a simple itch I wanted to scratch. So, it’s original to me, and that’s what counts.